How do I extract values from custom tags in Feedzy?
Feedzy Pro lets you extract values from custom XML tags in RSS feeds and map them to imported post fields, using custom tag magic tags in both the shortcode and the Feed to Post import wizard.
📝Note: This Premium feature is available only with the Developer and Agency plans. If you've already purchased one of the two plans, you need to have both the Lite & Pro versions of the plugin activated for the feature to work.
In this article
Overview
The plugin imports fields such as title, content, and so on. What if you want to fetch a custom tag's value, such as date updated or rating?
The regular tags that Feedzy can parse are the ones available in the import dropdown when clicking on the Insert Tag button:
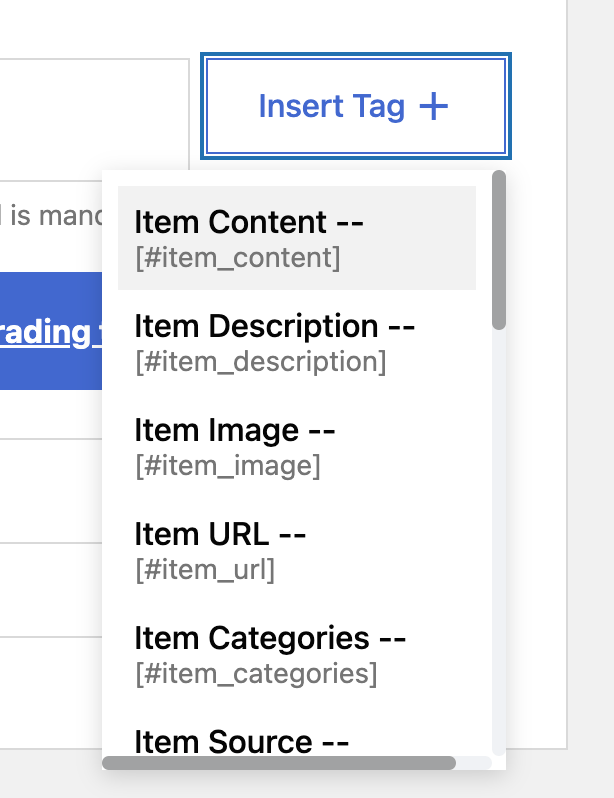
Apart from these, you can extract almost everything from the XML file using the custom tags, including the values available with the regular tags. For example, if you want to extract the URL of an item, you can use the regular [#item_url] tag or a custom tag - [#item_custom_url] (depending on how it's named in the XML file). This tutorial shows you how to do it.
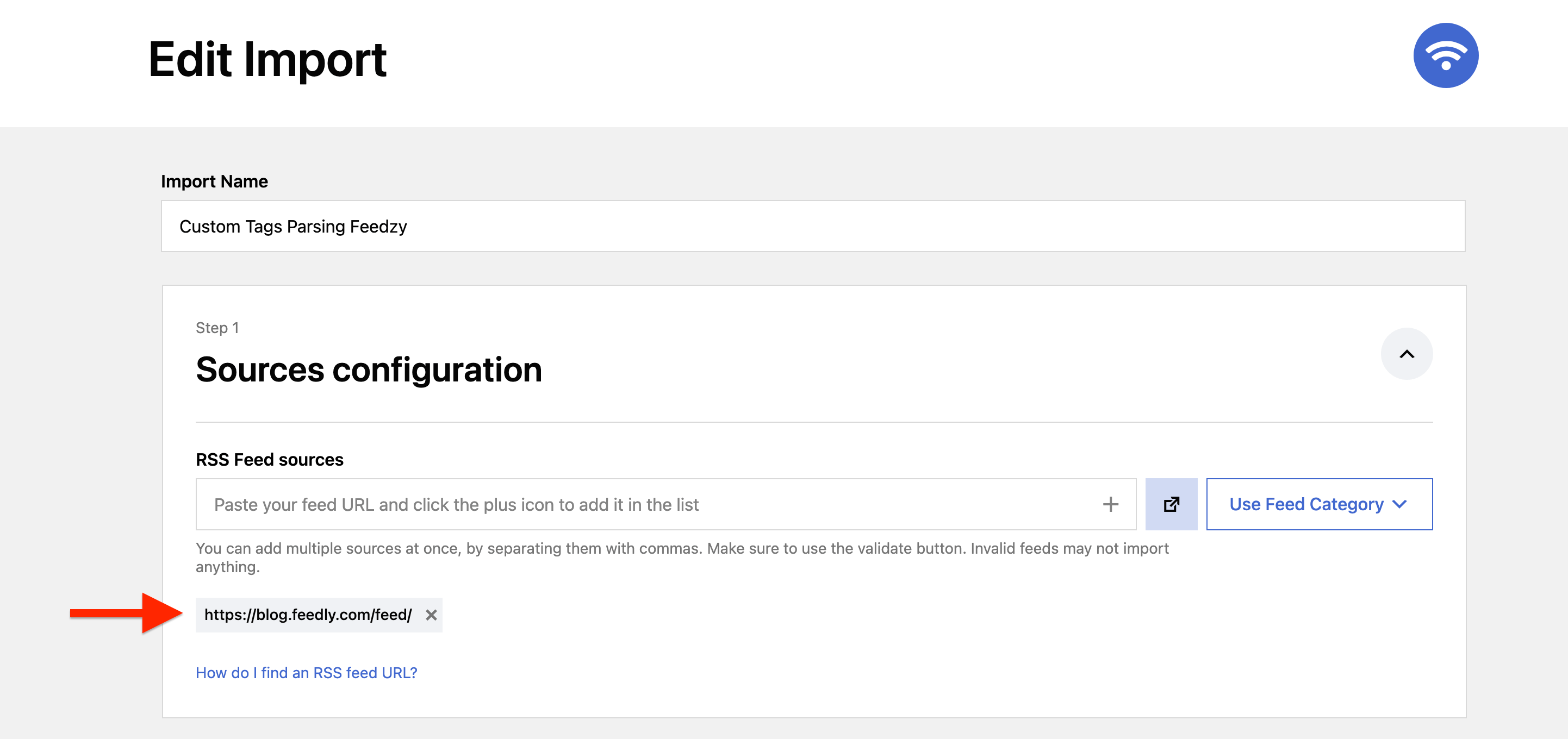
We have used an XML file from where we extracted values - https://blog.feedly.com/feed/.
One important thing that you need to keep in mind is the structure of the XML file. Sometimes, it might have different naming conventions, but the idea is that the main accordion ( here - "channel" ) is the Feed Level, and the accordions inside of it ( here - "items") are the Item Levels.
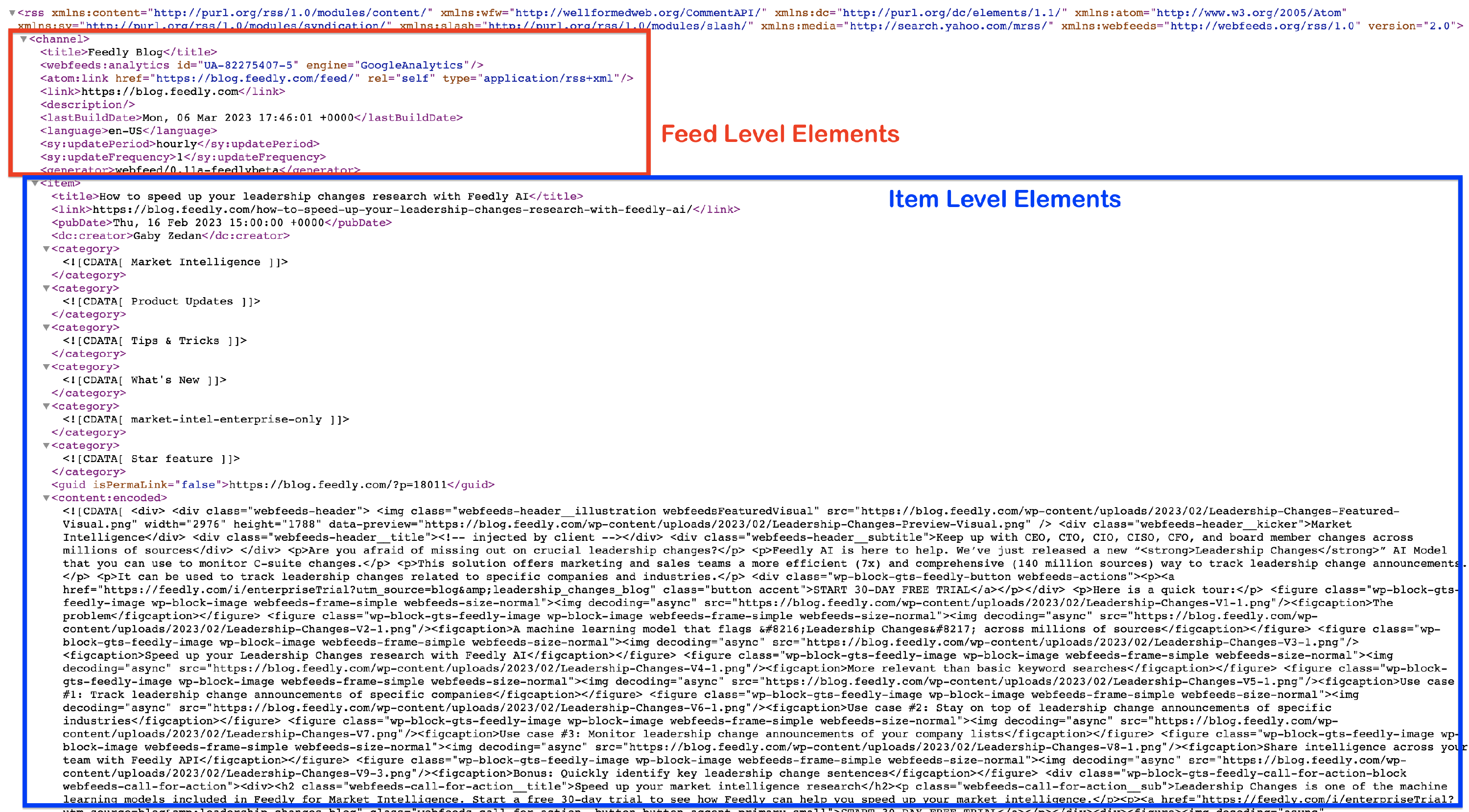
You can achieve it depending on how you are importing the posts:
Extract price using the shortcode
Follow the table below to understand how to provide the value of the mapping attribute of the shortcode:
| Element/Attribute | Value of 'mapping' attribute | Extracted value |
| Feed level element | ||
<title> | price=feed|title | Feedly Blog |
<link> | price=feed|link | https://blog.feedly.com |
| Item level element (each item will correspond to one element, so we will assume this is the first item) | ||
<updated> | price=pubDate | Thu, 16 Feb 2023 15:00:00 +0000 |
<dc:creator> | price=dc:creator | Gaby Zedan |
Examples
[feedzy-rss feeds="https://blog.feedly.com/feed/" price="yes" template="style1" mapping="price=feed|link"]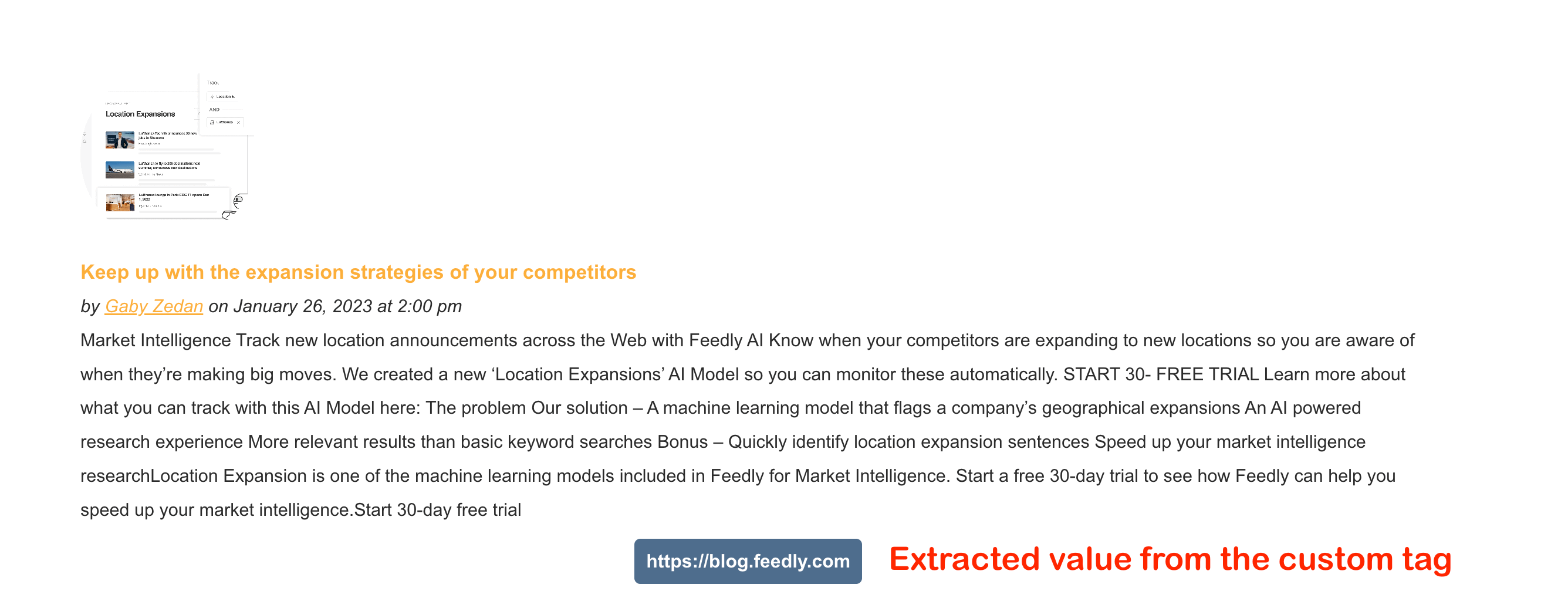
[feedzy-rss feeds="https://blog.feedly.com/feed/" price="yes" template="style2" mapping="price=dc:creator" max="10"]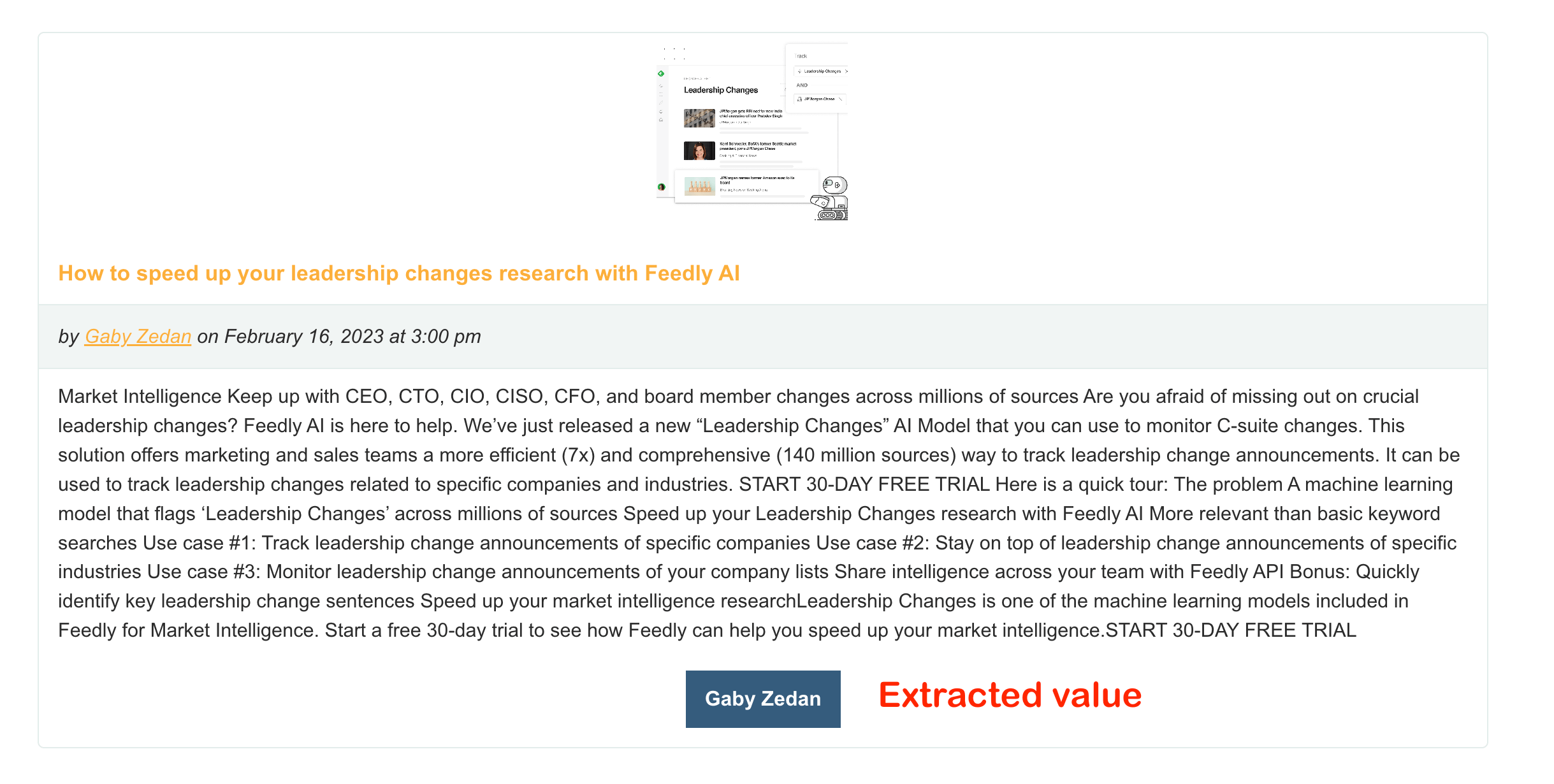
📝 Note: By default, the Shortcode block will display only 5 posts, but you can use the max parameter to display more. Check the full list of parameters here.
Feed to Post
Follow the table below to understand the format of the magic tags that you can use.
| Element/Attribute | Tag | Extracted value |
| Feed level element | ||
<title> | [#feed_custom_title] | Feedly Blog |
<lastBuildDate> | [#feed_custom_lastBuildDate] | Mon, 06 Mar 2023 17:46:01 +0000 |
| Item level element (each post will correspond to one element, so we will assume this is the first post) | ||
| [#item_custom_pubDate] | Thu, 16 Feb 2023 15:00:00 +0000 | |
<link> | [#item_custom_link] | https://blog.feedly.com/how-to-speed-up-your-leadership-changes-research-with-feedly-ai |
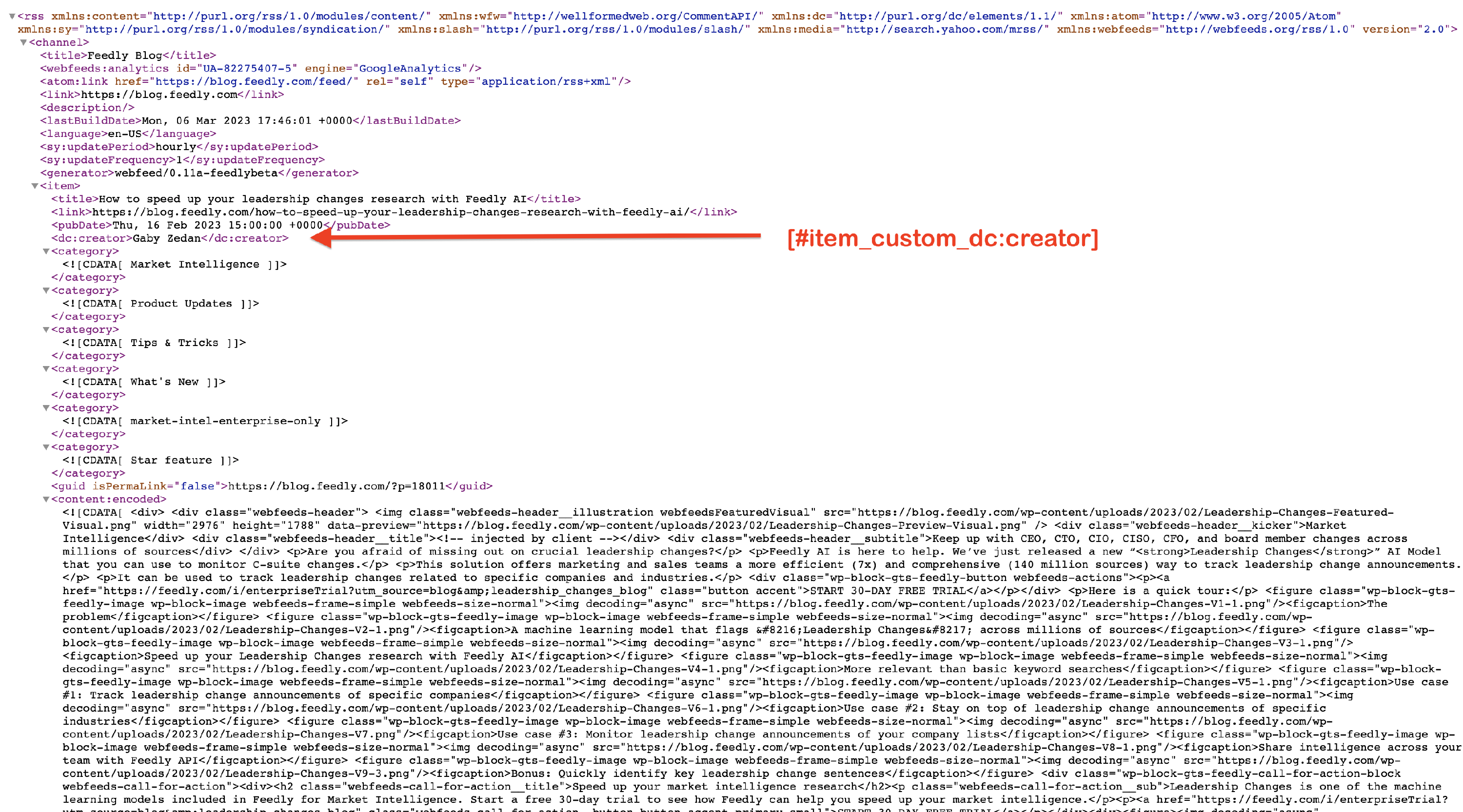
<dc:creator> | [#item_custom_dc:creator] | Gaby Zedan |
Let's try to import the creator using the above table. We want to fetch this creator:
1. Add a new import feed with this URL.
2. Configure the filters of the feed to get the desired results.
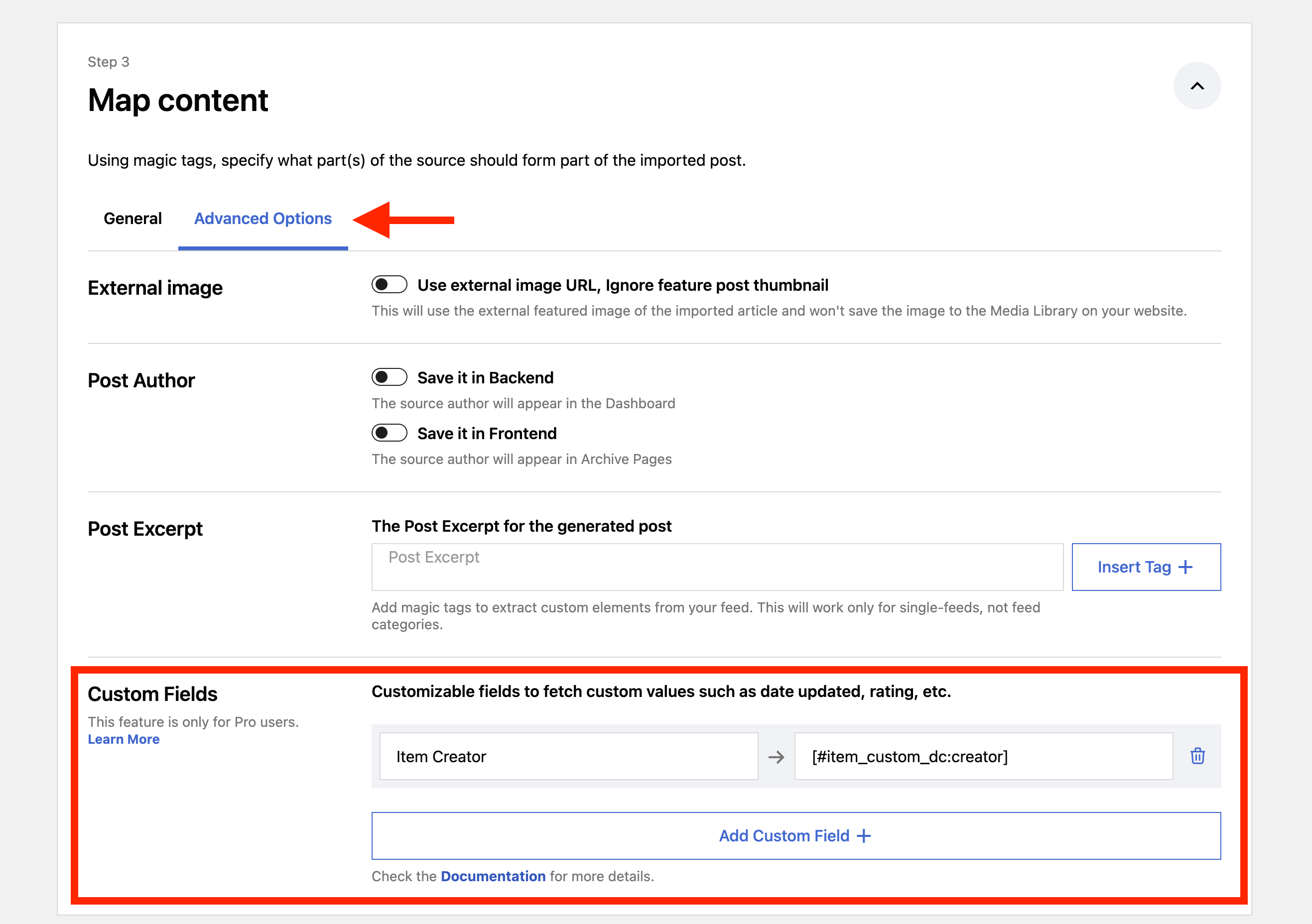
3. In the Map Content area > Advanced Options, make sure you create a custom field as follows:
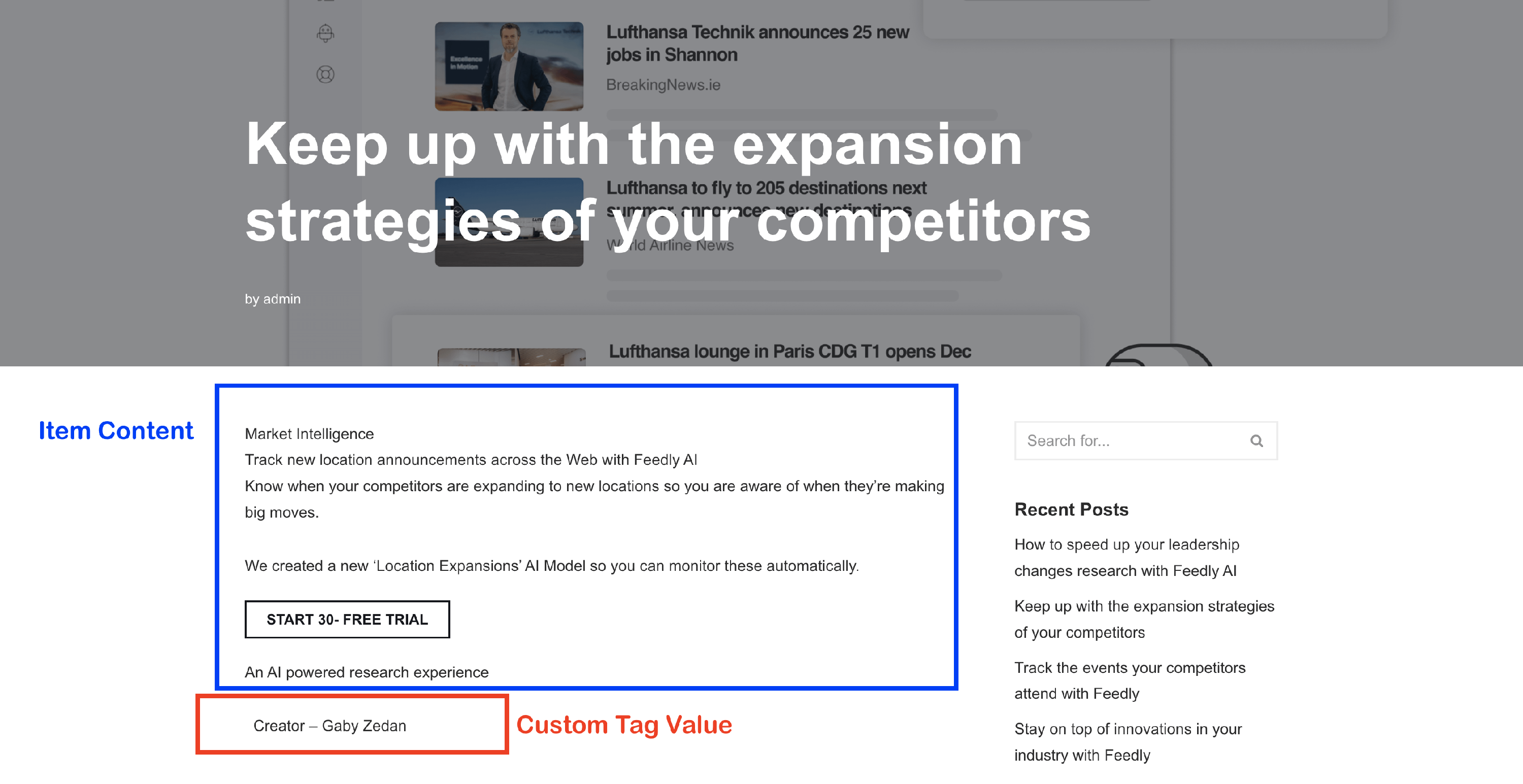
You can also add the tag [#item_custom_dc:creator] in the " Content" field in the General tab of the Map Content to see the extracted value on the post itself.
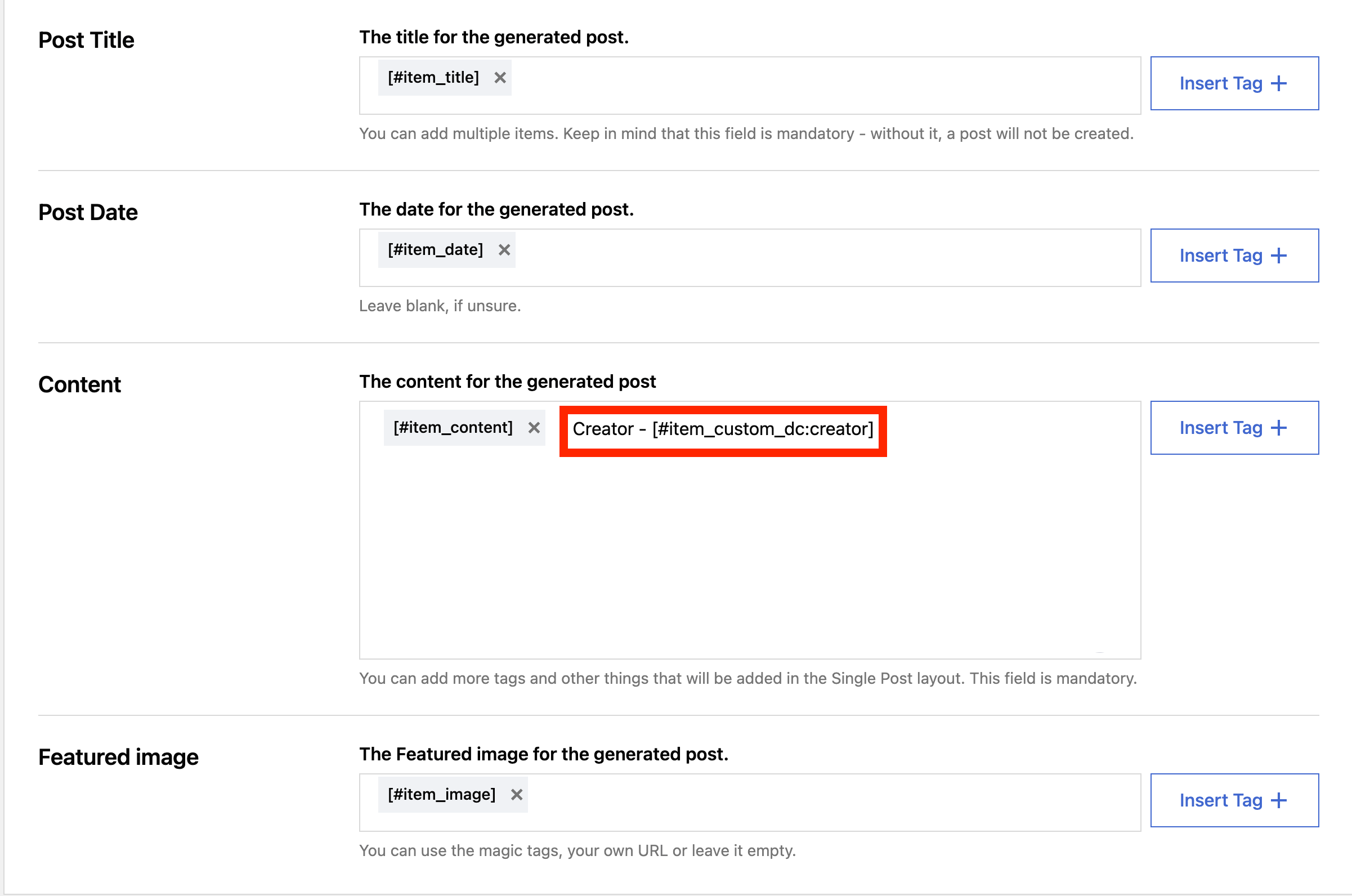
Result
Inside the editor, it will create a new custom field named "Item Creator" for each post and fetch the value in it.
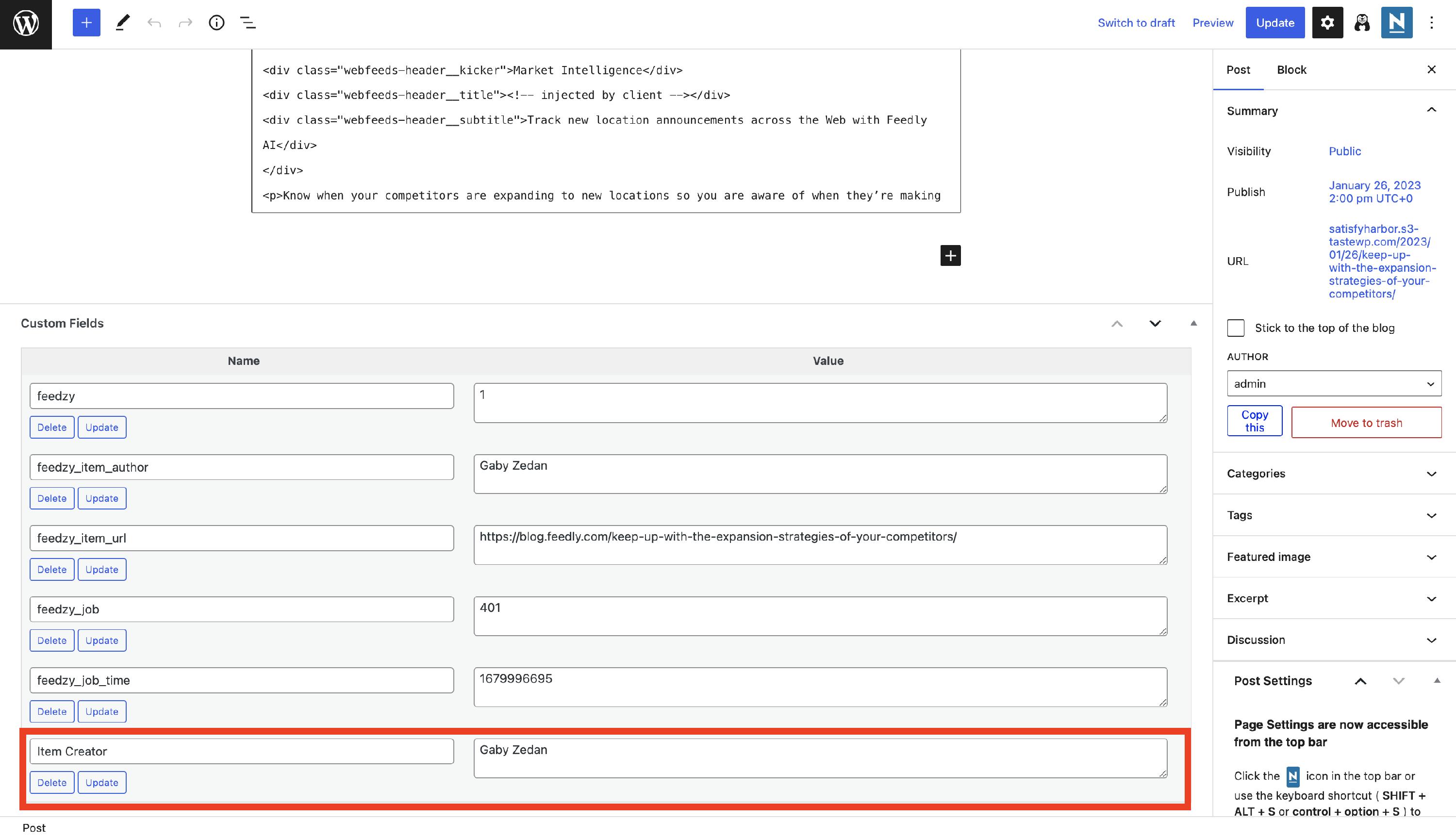
📝 Note: Gutenberg/Block Editor doesn't have custom fields enabled by default. If you don't see the above screen, enable them by using these steps.
Additional Feature: Custom Field Actions
📝 Note: This Premium feature is available only with the Developer and Agency plans. Ensure both the Lite and Pro versions of Feedzy are activated to use this feature.
Feedzy now supports actions for custom fields, enabling users to dynamically modify or enrich the custom field values imported. This is particularly useful when you want to adjust or enhance specific imported content directly during the import process.
Custom field actions can be applied to fetched values, such as translations, content trimming, or AI-generated rewrites. This flexibility is accessible through the Map Content area in the Feedzy import wizard.
Below is a quick overview of how to configure and utilize this feature:
1. Navigate to the Map Content section during the Feedzy import setup.
2. Add a new custom field using the Custom Fields section. Provide a key name and assign the respective value or magic tag. 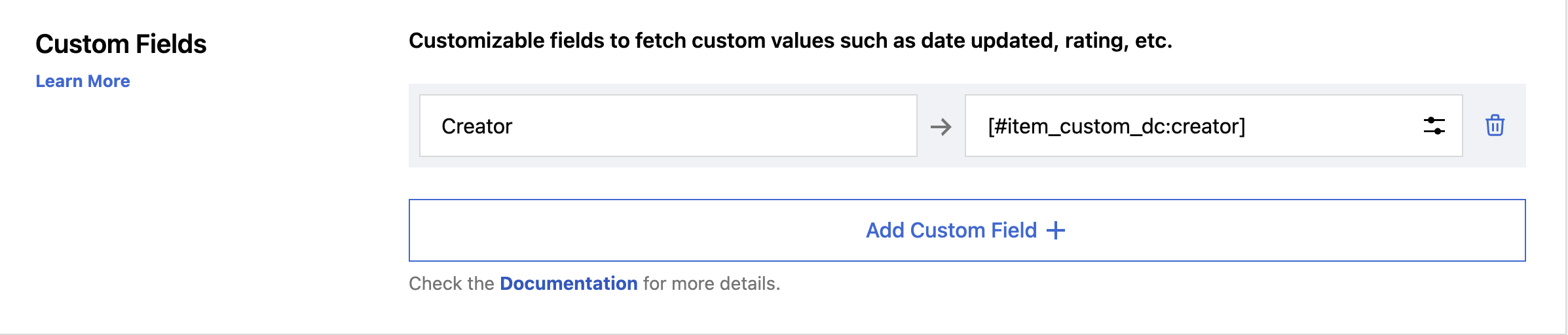
3. Click the Action Settings icon next to the custom field to open the action's configuration modal.
4. Select one or more actions from the available options, such as Trim Content, Translate, Search/Replace, or Rewrite with AI. You can also add new actions or remove unnecessary ones. 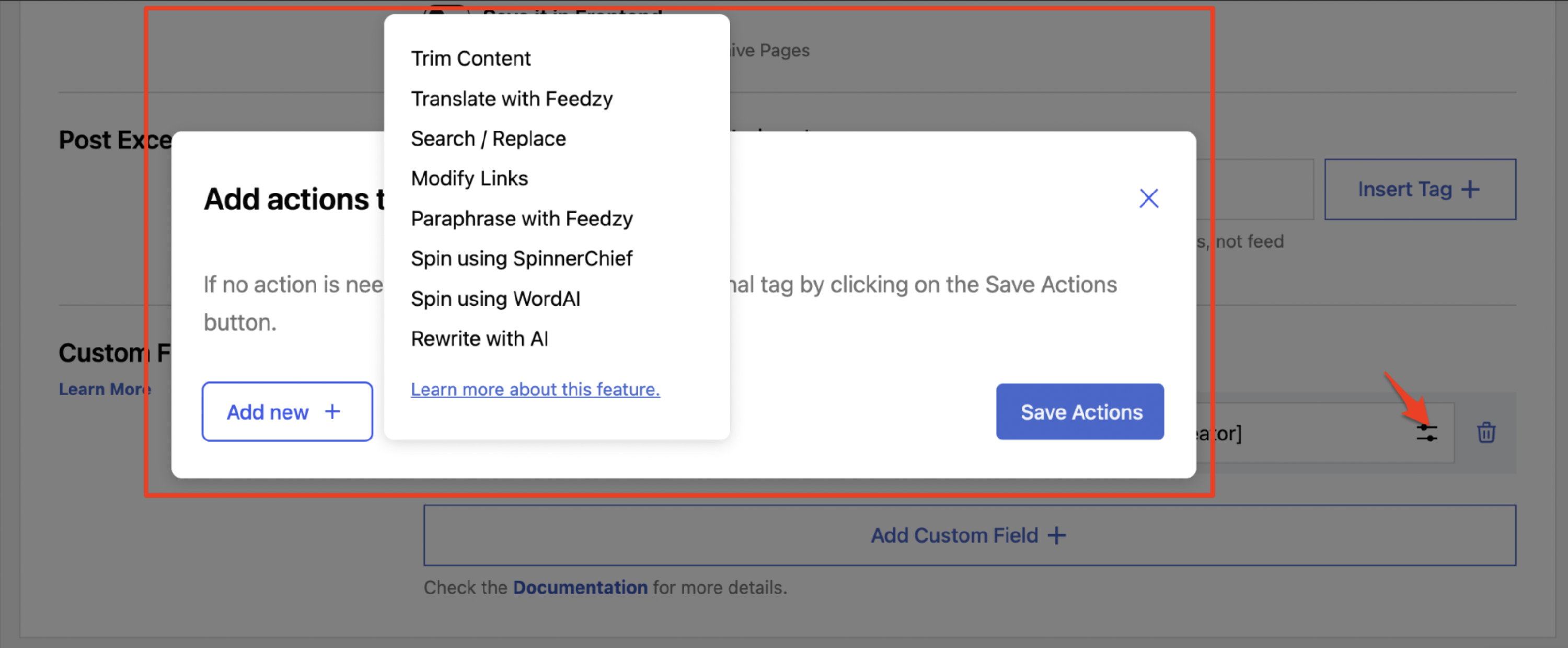
5. Once the actions are configured, click Save Actions. These will be applied to the imported custom field values during the feed import. With these enhancements, Feedzy enables you to tailor your imports to fit the specific needs of your website or application, ensuring maximum flexibility and efficiency.
Useful Resources
Extracting a subset of items or the Nth element only
In the following example, we'll use a source with multiple creators on each post( click to see the full source).
<?xml version='1.0' encoding='UTF-8'?>
<rss xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:atom="http://www.w3.org/2005/Atom" xmlns:content="http://purl.org/rss/1.0/modules/content/" version="2.0">
<channel>
<title>RCIGM Publications</title>
<link>https://pubmed.ncbi.nlm.nih.gov/rss-feed/?feed_id=1854v2hhZnt_mhFdDPyD32xkxaSsIVGKhpnUhzqvOF03NQ8Ic3&ff=20210924094051&utm_medium=rss&utm_content=1854v2hhZnt_mhFdDPyD32xkxaSsIVGKhpnUhzqvOF03NQ8Ic3&fc=20210322141756&utm_source=Chrome&utm_campaign=pubmed-2&v=2.15.0</link>
<description>RCIGM Publications: Latest results from PubMed</description>
<atom:link href="https://pubmed.ncbi.nlm.nih.gov/rss-feed/?feed_id=1854v2hhZnt_mhFdDPyD32xkxaSsIVGKhpnUhzqvOF03NQ8Ic3&ff=20210924094051&utm_medium=rss&utm_content=1854v2hhZnt_mhFdDPyD32xkxaSsIVGKhpnUhzqvOF03NQ8Ic3&fc=20210322141756&utm_source=Chrome&utm_campaign=pubmed-2&v=2.15.0" rel="self"/>
<docs>http://www.rssboard.org/rss-specification</docs>
<generator>PubMed RSS feeds (2.15.0)</generator>
<language>en</language>
<lastBuildDate>Fri, 24 Sep 2021 13:40:53 +0000</lastBuildDate>
<pubDate>Tue, 21 Sep 2021 06:00:00 -0400</pubDate>
<ttl>120</ttl>
<item>
<title>Insights into the expanding phenotypic spectrum of inherited disorders of biogenic amines</title>
<link>https://pubmed.ncbi.nlm.nih.gov/34545092/?utm_source=Chrome&utm_medium=rss&utm_campaign=pubmed-2&utm_content=1854v2hhZnt_mhFdDPyD32xkxaSsIVGKhpnUhzqvOF03NQ8Ic3&fc=20210322141756&ff=20210924094051&v=2.15.0</link>
<description>Inherited disorders of neurotransmitter metabolism are rare neurodevelopmental diseases presenting with movement disorders and global developmental delay. This study presents the results of the first standardized deep phenotyping approach and describes the clinical and biochemical presentation at disease onset as well as diagnostic approaches of 275 patients from the registry of the International Working Group on Neurotransmitter related Disorders. The results reveal an increased rate of...</description>
<content:encoded>...</content:encoded>
<guid isPermaLink="false">pubmed:34545092</guid>
<pubDate>Tue, 21 Sep 2021 06:00:00 -0400</pubDate>
<dc:creator>Elijah H Bolin</dc:creator>
<dc:creator>Yevgeniya Gokun</dc:creator>
<dc:creator>Paul A Romitti</dc:creator>
<dc:creator>Sarah C Tinker</dc:creator>
<dc:creator>April D Summers</dc:creator>
<dc:creator>Paula K Roberson</dc:creator>
<dc:creator>Charlotte A Hobbs</dc:creator>
<dc:creator>Sadia Malik</dc:creator>
<dc:creator>Lorenzo D Botto</dc:creator>
<dc:creator>Wendy N Nembhard</dc:creator>
<dc:creator>National Birth Defects Prevention Study</dc:creator>
.
.
.In the following examples, you can see how the magic tags were used in the import wizard and the output result.
The default case - the plugin will extract only the first item:
[#item_custom_dc:creator]
Elijah H BolinExample 1 - extracting only the third item
[#item_custom_dc:creator[3]]
Paul A RomittiExample 2 - extracting the second, fourth, and sixth items
[#item_custom_dc:creator[2]][#item_custom_dc:creator[4]][#item_custom_dc:creator[6]]
Yevgeniya Gokun
Sarah C Tinker
Paula K Roberson