Monitoring Token Usage and Costs
FreshRank uses AI models that charge based on token usage. This guide shows you where to monitor your usage and costs to help you track spending and optimize your AI budget.
Note: Read our guide on token usage to learn what tokens are, what affects usage in FreshRank, real-world cost examples and tips on optimizing costs.
Where to Monitor Token Usage and Costs
FreshRank provides token usage information in multiple locations, but for accurate cost tracking, always check your AI provider's dashboard (OpenAI or OpenRouter) for actual billing. Here’s where you can monitor your usage and costs:
- AI Provider Dashboard
- System Status Card
- Analysis Results Page
- Draft Details Page
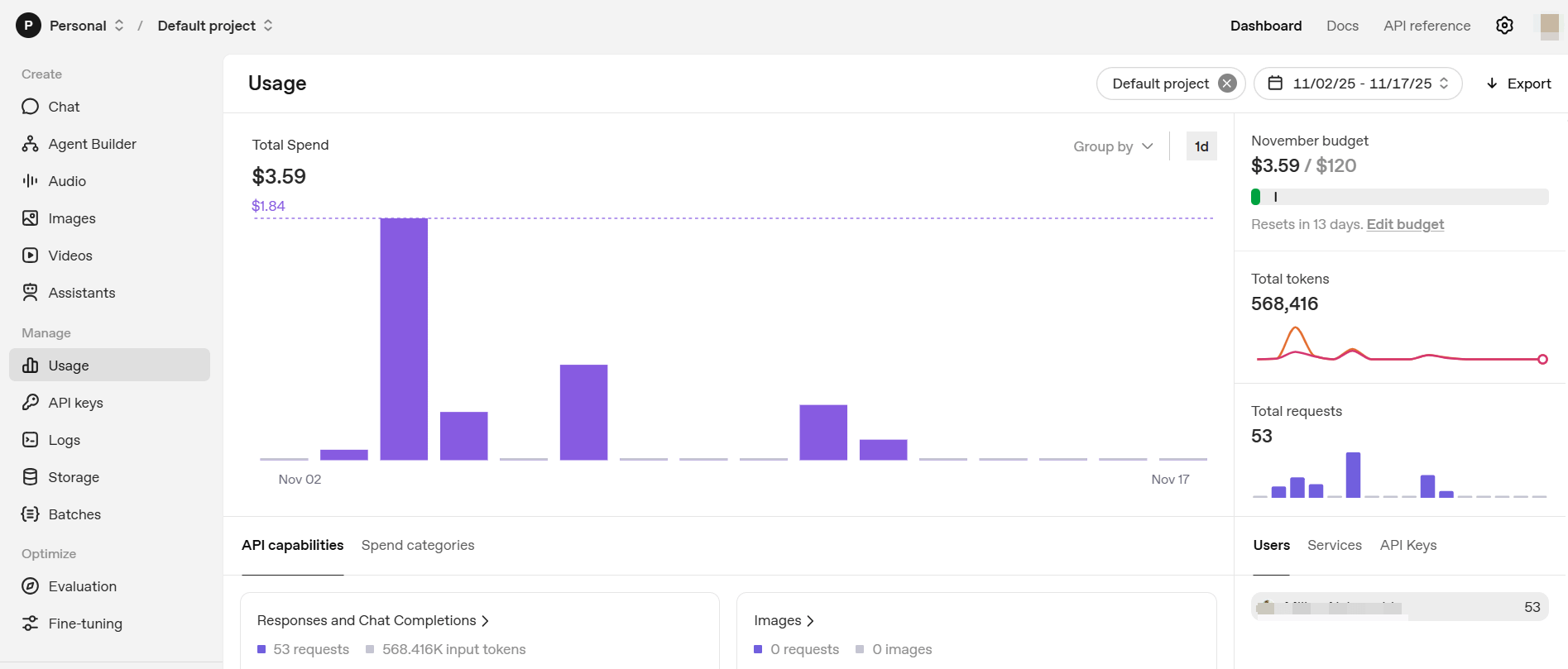
Location 1: AI Provider Dashboard (Most Accurate)
The most reliable place to monitor token usage and costs is directly with your AI provider. These dashboards show actual usage and billing, not estimates.
For OpenAI Users
- Go to OpenAI Usage Dashboard
- Visit platform.openai.com/usage
- Sign in with your OpenAI account
- What You'll See:
- Actual costs charged (not estimates)
- Daily token usage graphs
- Cost breakdown by model
- Historical usage trends
- Current billing period totals
- Remaining credits or quotas
- Real-time usage updates
- Set Up Spending Alerts:
- Go to platform.openai.com/account/limits
- Set monthly spending limits
- Enable email alerts for spending thresholds
- Prevent unexpected overages
Why check here:
- ✅ 100% accurate billing information
- ✅ Includes all API usage (FreshRank + any other apps)
- ✅ Real-time cost updates
- ✅ Historical data and trends
- ✅ Downloadable usage reports
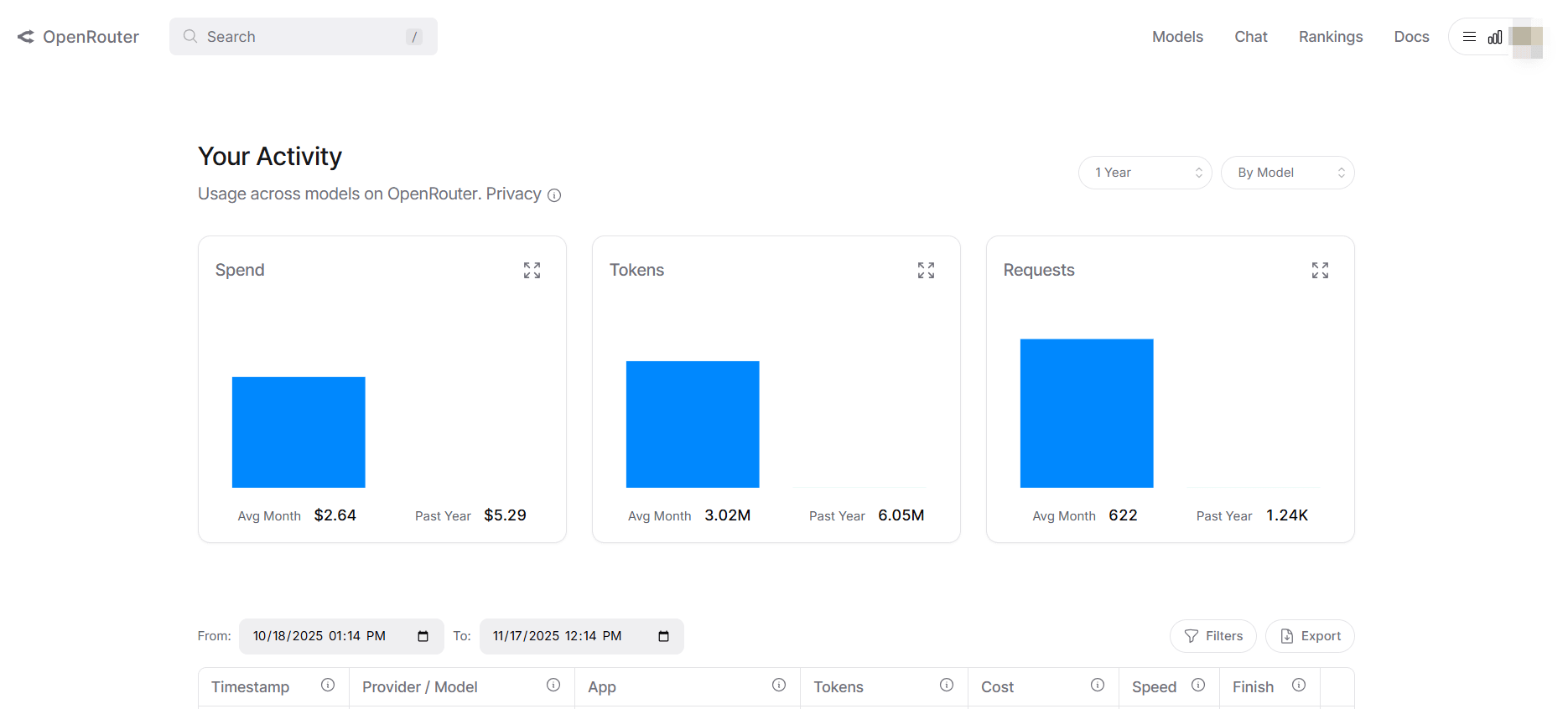
For OpenRouter Users
⚠️ Important: If you use OpenRouter, this is the ONLY place to see accurate costs. FreshRank cannot estimate OpenRouter costs.
- Go to OpenRouter Activity Page
- Visit openrouter.ai/activity
- Sign in with your OpenRouter account
- What You'll See:
- Actual costs per request
- Request history by model
- Credit balance (current funds)
- Daily/weekly/monthly spending summaries
- Model-by-model cost breakdown
- Cost per operation
- Check Credit Balance:
- Visit openrouter.ai/credits
- See remaining credits
- Add credits before running low
- Set up low-balance notifications
Why check here:
- ✅ ONLY source for OpenRouter cost data
- ✅ Real-time credit balance
- ✅ Per-request cost breakdown
- ✅ Supports 450+ models across multiple providers
- ✅ Unified billing across all models
Location 2: System Status Card (FreshRank Estimates)
The System Status card in FreshRank provides a quick overview of your token usage with estimated costs for OpenAI models.
How to Access
- Go to FreshRank AI → Settings
- Look at the right column (third card)
- Find the System Status card and look for Token Usage and Costs card
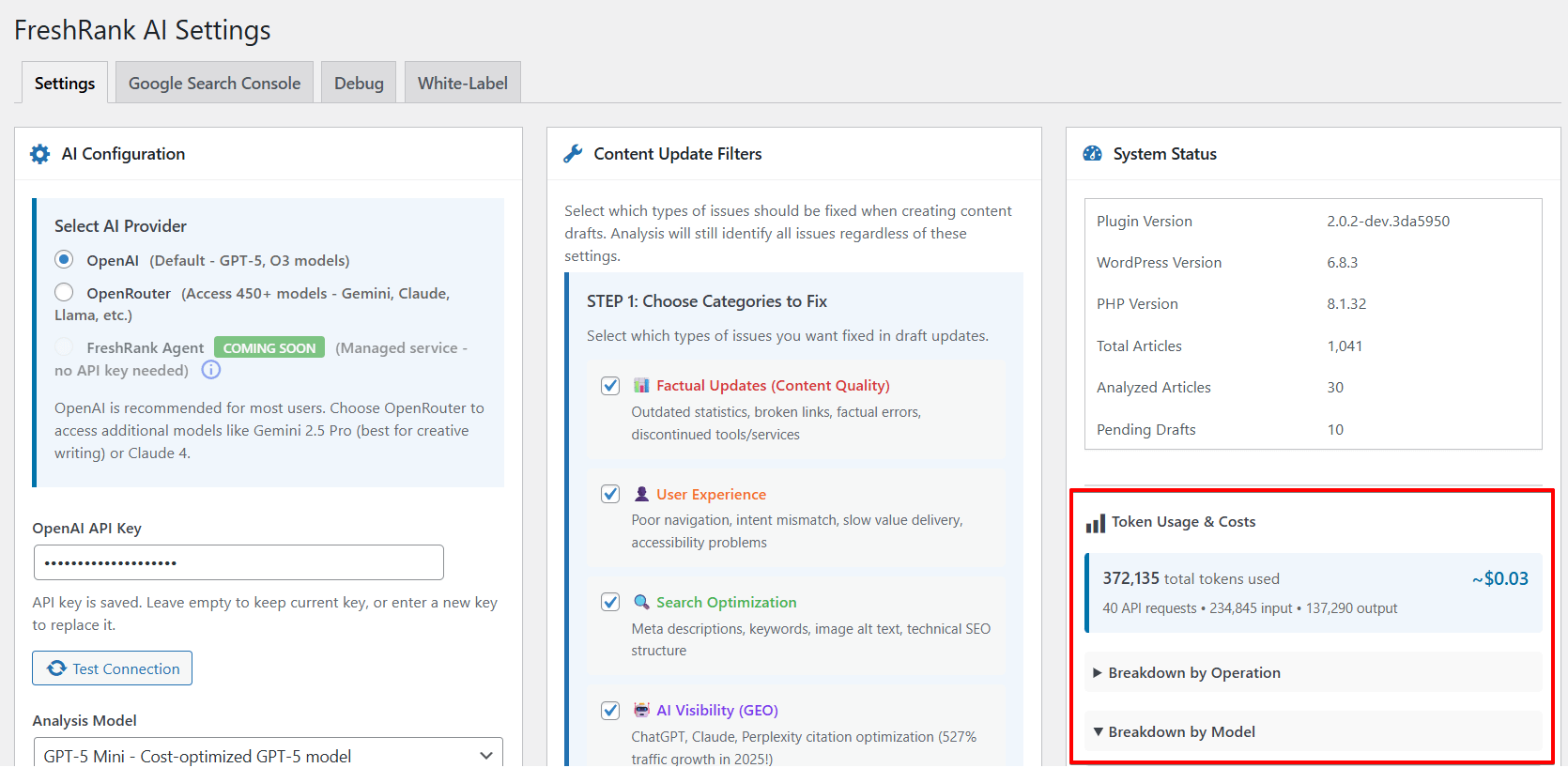
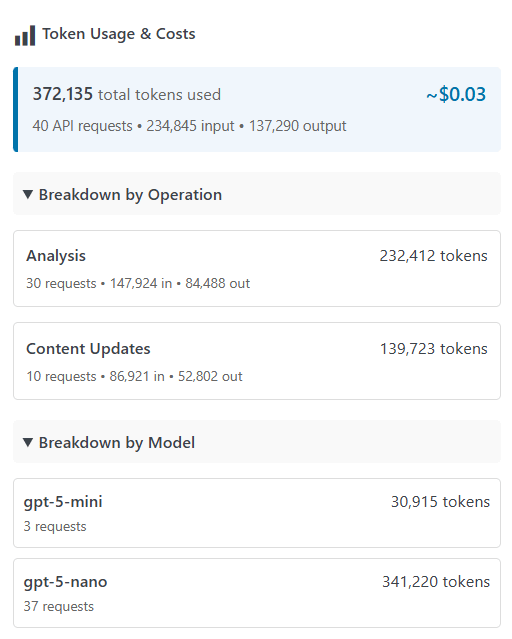
Token Usage Section:
- Total Tokens Used: Aggregate of all operations
- Number of API requests made
- Input tokens consumed
- Output tokens consumed
- Estimated Cost: Total approximate cost (e.g., ~$12.45)
- Breakdown by Operation:
- Analysis token usage (total across all analyses)
- Content updates token usage (total across all drafts)
- Breakdown by Model:
- Token usage per AI model
- Shows which models you've used and how much
How FreshRank Calculates Costs
FreshRank estimates costs using current OpenAI pricing (per 1 million tokens):
- Input Cost = (Input Tokens ÷ 1,000,000) × Model Input Price
- Output Cost = (Output Tokens ÷ 1,000,000) × Model Output Price
- Total Cost = Input Cost + Output Cost
⚠️ Important Limitations:
- OpenRouter costs show as $0 - FreshRank only estimates costs for OpenAI models. For OpenRouter, check usage at openrouter.ai/activity
- Estimates are approximate based on current OpenAI pricing, which may change before the plugin is updated to reflect those changes.
What This Tells You
Total Token Count & Cost:
- Your cumulative usage across all time
- Estimated total spending on AI operations (OpenAI only)
- Shows overall AI consumption
Operation Breakdown:
- See if analysis or draft creation uses more tokens and costs more
- Identify which operation to optimize
- Balance your workflow based on token usage and costs
Model Breakdown:
- Compare token usage and costs across different models
- Identify most/least expensive models you've used
- Make informed decisions about model selection
💡 Refresh Rate: Token statistics are cached for 5 minutes and update after each completed operation.
Location 3: Analysis Results Page (Per-Operation Details)
Each analysis shows specific token usage and cost for that individual operation.
How to Access
- Go to FreshRank AI → Dashboard
- Find a post with "Ready" status
- Click "View Details" in the Analysis column
- Scroll to the bottom of the analysis results
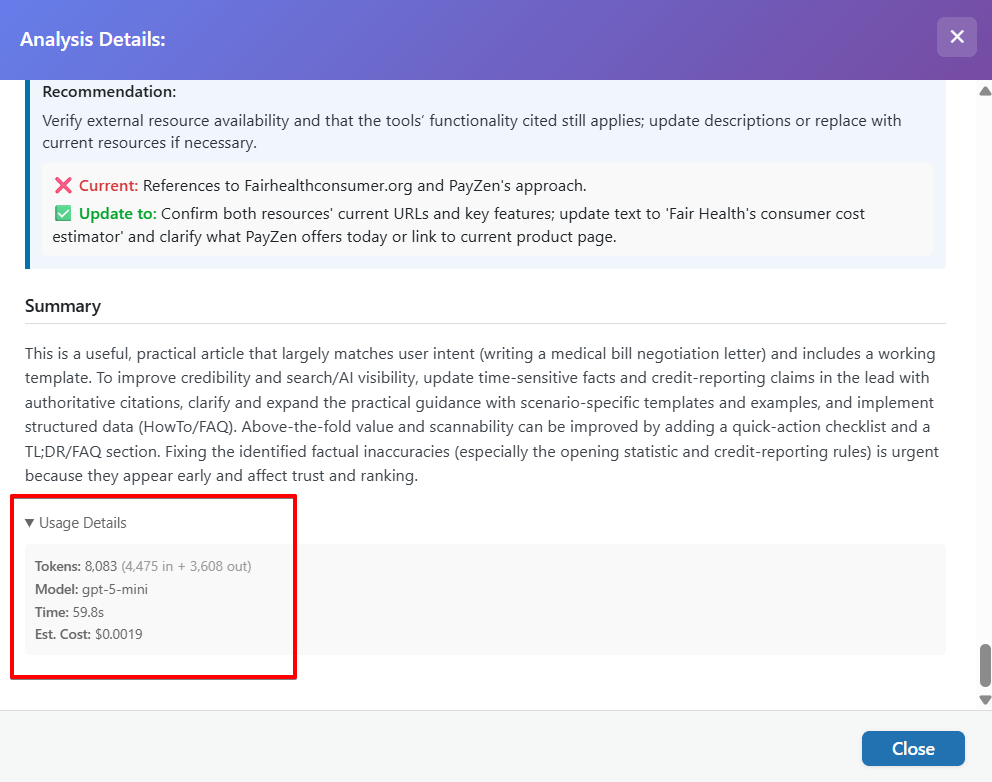
What You'll See:
- Tokens: Total tokens used for this analysis
- Input tokens (your content)
- Output tokens (AI's analysis)
- Model: Which AI model was used (e.g., "GPT-5", "Claude Sonnet")
- Time: How long the analysis took (in seconds or minutes)
- Estimated Cost: Approximate cost for this specific analysis (e.g., $0.08)
💡 Tip: Check this after analyzing different content lengths to understand how post size affects token usage and costs.
Location 4: Draft Details Page (Per-Operation Details)
The Draft Details page shows specific token usage and cost for that individual draft creation.
How to Access
- Go to FreshRank AI → Dashboard
- Find a post that you created a draft for
- Click "View Draft Details" in the Status column
- Scroll to the bottom of the details page
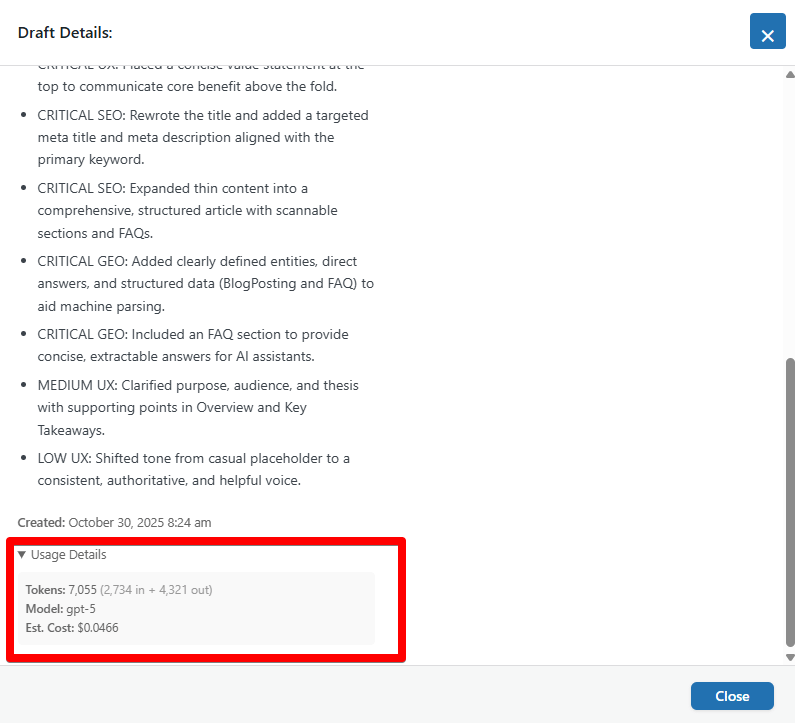
What You'll See:
- Tokens: Total tokens used for this analysis
- Input tokens (your content)
- Output tokens (AI's analysis)
- Model: Which AI model was used (e.g., "GPT-5", "Claude Sonnet")
- Estimated Cost: Approximate cost for this specific analysis (e.g., $0.08)
💡 Tip: Check this after applying different content filters to understand how the number of issues you fix affects token usage and costs.